Every time you type a question into Google, you get an answer in under a second — pulled from billions of web pages. That feels like magic. It isn’t. It’s a system built on three repeatable stages, and once you understand them, you’ll use search smarter, build better websites, and make sense of why some pages rank and others don’t.
This guide covers search engine basics from the ground up: what a search engine is, how it works step by step, the different types that exist, and why any of this matters for you.
What Is a Search Engine?
A search engine is software that helps you find information on the internet by matching your query to a database of web content it has already collected and organized.
The distinction worth making upfront: a search engine is not the internet. It’s an index of the internet — like a very fast card catalog for a library that never stops growing. Google, Bing, Yahoo, DuckDuckGo, and Baidu are all search engines. They differ in scale, privacy approach, and algorithm design, but they all work on the same core architecture.
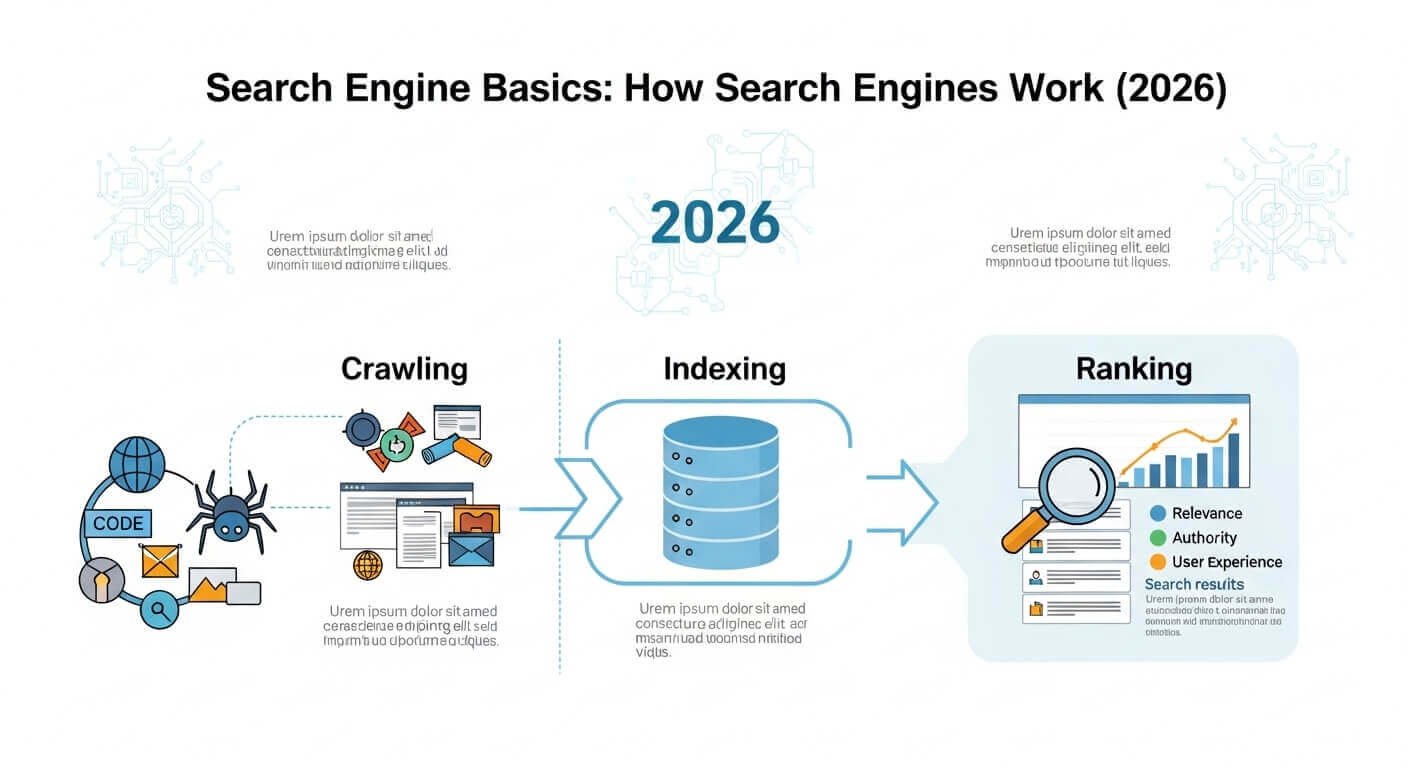
How a Search Engine Works: The Three Core Stages
Stage 1 — Crawling: Finding Pages
Search engines deploy automated programs called crawlers (also called spiders or bots). Google’s is called Googlebot. These bots move across the web by following links — from one page to another, then to the next — much like you might click from a Wikipedia article to a source it cites.
When a crawler visits a page, it downloads the content and follows every outbound link it finds. That’s how it discovers new pages. The crawler keeps a queue of URLs to visit, constantly refreshing it as new links appear.
A few things affect whether your page gets crawled: how well other sites link to it, whether your robots.txt file blocks crawlers, and how fast your server responds. Pages buried deep in a site with no inbound links may never get crawled at all.
Stage 2 — Indexing: Storing and Understanding Content
After crawling, the search engine processes each page and adds it to its index — a massive database. But it’s not just storing a copy of the page. It’s analyzing the content to understand what the page is actually about.
During indexing, the engine notes:
- The words used and how often
- The structure (headings, paragraphs, metadata)
- The images and their alt text
- The links pointing to and from the page
- The page’s technical health (load speed, mobile-friendliness)
Google’s index reportedly contains hundreds of billions of web pages. Bing and other engines maintain their own separate indexes. When you search, you’re not searching the live web — you’re searching this stored index. That’s why results can occasionally be slightly out of date.
Stage 3 — Ranking: Deciding What Rises to the Top
This is where search engines differ most sharply from each other. Once the index is built, the ranking algorithm sorts through relevant results and decides which ones to show first.
Google uses a system called PageRank (named after co-founder Larry Page, not “web page”) as one foundation of its algorithm, alongside hundreds of other signals. These signals include:
- Relevance — how closely the page’s content matches the query
- Authority — how many high-quality sites link to this page
- User signals — do people click it? Do they stay? Do they come back?
- Page experience — is it fast, mobile-friendly, and secure (HTTPS)?
- Freshness — for time-sensitive queries, newer content ranks higher
Google’s algorithm is updated thousands of times a year, with major “core updates” announced publicly a few times annually. The February 2026 core update, for instance, doubled down on reducing clickbait content and rewarding genuine expertise.
The Main Components of a Search Engine
Understanding the basic components of a search engine helps clarify how each stage is supported technically:
- Web crawler — the bot that discovers and fetches content. Most major engines run multiple crawlers simultaneously, prioritizing pages that update frequently or have high authority.
- Index database — the stored, structured representation of crawled content. This is what you’re actually querying when you search.
- Query processor — the component that takes your search terms, interprets intent (are you looking for information, trying to buy something, navigating to a site?), and matches them to index entries.
- Ranking engine — applies the algorithm to the matched results and produces an ordered list. This is where machine learning models like Google’s RankBrain and BERT play a role, helping interpret natural language queries.
- Results interface (SERP) — the Search Engine Results Page you see. In 2026, this often includes AI-generated overviews, featured snippets, local results, image packs, and video results, alongside traditional blue links.
Types of Search Engines
Not all search engines are the same type. There are four main categories:
- Crawler-based search engines build their own indexes using crawlers. Google, Bing, and Baidu are the big examples. These are the most comprehensive and the ones most people mean when they say “search engine.”
- Human-powered directories (also called web directories) relied on human editors to categorize sites. Yahoo Directory, once a major player, worked this way. Most are now defunct or niche, since maintaining them manually at web scale is impractical.
- Hybrid search engines combine crawlers with human editorial input. Early Yahoo used this model. Some vertical search engines (job boards, academic databases) still do.
- Meta-search engines don’t build their own indexes. Instead, they query multiple search engines and combine the results. DuckDuckGo uses a mix of Bing’s index and other sources. Dogpile is a classic meta-search example.
- Vertical search engines focus on a specific domain: Google Scholar (academic papers), Google Images, Yelp (local businesses), and Amazon (products). They’re purpose-built for one type of content.
How Google Search Works Specifically
Google is worth calling out because it processes roughly 8.5 billion searches per day, according to estimates from Internet Live Stats. While Google doesn’t publish exact figures, the scale shapes how the web is built.
Google’s process follows the same three stages above, but with proprietary layers on top:
- Knowledge Graph — a database of entities (people, places, things, concepts) and their relationships. When you search “Who invented the telephone?”, Google can answer directly from the Knowledge Graph, not just link to pages about it.
- BERT and MUM — neural language models that help Google understand natural language. BERT (Bidirectional Encoder Representations from Transformers) processes queries in context rather than keyword-by-keyword. MUM (Multitask Unified Model) can process text, images, and multiple languages simultaneously.
- AI Overviews — introduced widely in 2023 and expanded significantly through 2025–2026, these are AI-generated summaries that appear at the top of results for many queries. They draw from multiple indexed sources and are now present on roughly 19% of all SERPs, according to data from Semrush’s 2025 SERP feature analysis.
Search Engine Optimization (SEO) Basics
Understanding how search engines work is the foundation of search engine optimization — the practice of making your content easier for search engines to find, understand, and rank highly.
The basic principles of SEO follow directly from the three stages:
- For crawling: Make sure your site is accessible. No crawler-blocking errors in your robots.txt, fast server response times, and a clear site structure with internal links so crawlers can find every page.
- For indexing: Write clear, original content. Use proper heading structure (H1, H2, H3). Add descriptive alt text to images. Make sure your page has a unique, relevant title and meta description.
- For ranking: Build content that genuinely answers a user’s question better than existing results. Earn backlinks from credible sites. Prioritize page speed and mobile usability. Demonstrate expertise and trustworthiness — Google’s guidelines refer to this as E-E-A-T: Experience, Expertise, Authoritativeness, and Trustworthiness.
How to Do a Basic Search More Effectively
Most people use one or two words. A few simple habits make searches much more useful:
- Use quotation marks to search for an exact phrase:
"search engine basics"only returns pages with that exact string. - Use a minus sign to exclude a word:
jaguar -carReturns results about the animal, not the vehicle. - Use site: to search within one website:
site:wikipedia.org search enginefinds search engine content only on Wikipedia. - Use filetype: to find specific formats:
how search engine works filetype:pdffinds PDF documents on the topic.
These operators work in Google, Bing, and DuckDuckGo.
FAQ: Search Engine Basics
Q: What is the difference between a search engine and a browser?
A browser (like Chrome, Firefox, or Safari) is the software you use to access the internet and view web pages. A search engine (like Google or Bing) is a service that helps you find pages. You access a search engine through a browser. Chrome is a browser; Google is a search engine. They’re made by the same company but serve different functions.
Q: How does a search engine decide what order to show results in?
Search engines use ranking algorithms that evaluate hundreds of factors simultaneously. The most important include: how relevant the content is to the query, how many authoritative sites link to the page, how well the page serves user needs based on engagement signals, and technical quality factors like load speed and mobile usability.
Q: What does “indexing” mean for a website?
Indexing means a search engine has visited, analyzed, and stored your page in its database. An indexed page can appear in search results. You can check if your page is indexed in Google by typing it site:yourdomain.com into Google Search. If your page doesn’t appear, it may have technical issues blocking indexing, or it may simply not have been discovered yet.
Q: Is DuckDuckGo a real search engine, or does it just use Google?
DuckDuckGo is a real search engine, but it doesn’t build its own full crawler-based index from scratch the way Google does. It uses a combination of Bing’s index, its own crawlers, and data from other sources. Its key differentiator is that it doesn’t track user search history or build personal profiles — a meaningful privacy distinction for many users.
Q: How long does it take a new website to appear in Google search results?
It varies. Google typically discovers and indexes new pages from established sites within days. A brand new site with no inbound links can take weeks to months before Googlebot discovers and indexes it. Submitting your sitemap through Google Search Console can speed this up significantly.
Q: What is a search engine algorithm?
An algorithm is a set of rules or instructions that a computer follows to complete a task. A search engine algorithm is the system of rules used to evaluate, score, and rank pages in response to a query. Google’s algorithm is updated thousands of times a year and includes sub-systems like PageRank, RankBrain, and the Helpful Content system. No one outside Google knows the full algorithm — and intentionally so.
Key Takeaways
Search engines work in three stages: crawling (discovering pages), indexing (storing and understanding them), and ranking (sorting by relevance and quality). The type of search engine you’re using — crawler-based, meta, or vertical — shapes what results you see and how fresh they are. Google’s dominance comes partly from the scale of its index and partly from its investment in natural language understanding through models like BERT and MUM.
For anyone building a website, understanding this process is the starting point for SEO. For anyone just searching, knowing how results are ranked makes you a more critical consumer of what appears on that first page.